部署准备
序号 | 类型 | 软件名称 | 说明 |
|---|---|---|---|
1 | 操作系统 | Windows Server 2003 或更高版本(RedHat 6.5或CentOS 7或Ubuntu 11) | 部署数据库服务器Oracle,内存建议为16G以上,内核数量为8个以上 |
2 | RedHat 6.5或CentOS 7或Ubuntu 11 | 部署Redis,建议内存为16G以上 | |
3 | Windows Server 2003 或更高版本RedHat 6.5或CentOS 7或Ubuntu 11 | 部署应用服务器,建议内存为16G以上,一般情况安装Tomcat | |
4 | 数据库 | Oracle Enterprise 11G | |
5 | Redis 3.0(或更高版本) | ||
6 | 应用服务器 | JDK 6(或更高版本) | |
7 | Tomcat 6.5(或更高版本) | ||
8 | 中心端应用 | Datamanager.dmp | 数据库导出文件 |
9 | Datacenter.dmp | 数据库导出文件 | |
10 | Datacenter.jar | 部署jar包 |
部署流程图

Oracle数据库安装与配置
安装前准备工作
确认Oracle数据库的安装操作系统及版本,从Oracle官网下载相应的Oracle Enterprise 11G安装程序;版本采用11.2.0.4
规划好部署方式(单机部署、还是集群部署);
规划好的数据库备份方案与容灾方案;
其它未涉及事宜。
Oracle数据库安装
请根据选择的操作系统进行Oracle数据库安装,Oracle数据库安装请参照数据库安装说明文档进行操作。
注意:Oracle安装时的字符集请选择ZHS16GBK。
Windows安装步骤参考《ORACLE 数据库安装步骤》
Oracle安装后配置
设置Process配置1600
用sys账号登录,修改Process参数,命令如下:
alter system set processes=1600 scope = spfile;修改180天要强制修改口令:
用sys账号登录,修改口令限期问题,命令如下:
Alter PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;设置参数SQLNET.EXPIRE_TIME
找到sqlnet.ora文件(在Oracle_Home\network\amdin目录下),打开文件,在文件中增加以下内容:
SQLNET.EXPIRE_TIME=20防火墙设置,设置1521端口可以外部防问,如果没有安装防火墙或防火墙关闭则可以不处理。
设置游标数(show parameter open_cursors;):
alter system set open_cursors=2000;对Oracle Users表空增加dbf文件,先查询dbf文件存放路径:
Select * from dba_data_files。增加dbf文件:
alter tablespace USERS add datafile 'Oracledbf文件路径\USERS02.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS03.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS04.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS05.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile 'Oracledbf文件路径\USERS06.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS07.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS08.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS09.DBF' size 500M autoextend on next 50M maxsize unlimited ; alter tablespace USERS add datafile ' Oracledbf文件路径\USERS10.DBF' size 500M autoextend on next 50M maxsize unlimited ;
Dmp导入
安装前准备工作
确定已经完成了Oracle数据库安装与配置步骤;
获得到datamanager.dmp与datacenter.dmp文件;
安装PLSQL工具。
用户创建及用户授权
Oracle 9i-11g版本
用sys账号(dba身份)登录PLSQL,打开sql文件,执行文件中的所有语句。
注意:要核对所有的语句是否执行成功。
Oracle12C及以上版本
单租用户
用sys账号(dba身份)登录PLSQL,打开sql文件,执行文件中的所有语句。
注意:要核对所有的语句是否执行成功。
多租用户
用sys账号(dba身份)登录PLSQL,打开sql文件,执行文件中的所有语句。
注意:要核对所有的语句是否执行成功。
Datamanager dmp导入
导入前检查
在导入dmp文件前,请核对DMP导入的前二个步骤已经成功执行完成。核对操作导入dmp的机器上可以执行imp命令操作及正确配置数据库的连接。
采用imp命令进行数据导入,完整命令如下:
Imp userid=datamanager/data file=datamanager文件目录/datamanager.dmp full=y空表不能导出处理,在datamanager下执行:
select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0把查询结果在PLSQL中执行,以空行数据进行导出处理。
Datacenter dmp导入
导入前检查
在导入dmp文件前,请核对DMP导入的前二个步骤已经成功执行完成。核对操作导入dmp的机器上可以执行imp命令操作及正确配置数据库的连接。
数据导入
采用imp命令进行数据导入,完整命令如下:
Imp userid=datacenter/data file=datacenter文件目录/datacenter.dmp full=y空表不能导出处理,在datacenter下执行:
select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0把查询结果在PLSQL中执行,以空行数据进行导出处理。
Redis数据库安装
安装前准备工作
确认Redis内存数据库安装的操作系统及版本,从http://redis.io/官网下载相应的安装程序(3.0以上的版本);
规划好部署方式(单机部署、还是集群部署),如果是集群部署建议采用Codis,否则建议单机部署;
其它未涉及事宜。
Redis数据库安装
Redis安装后配置
Redis单机配置
设置appendfsync
打开redis.conf文件,设置
appendfsync no设置对外服务地址:
bind 127.0.0.1设置最大的内存使用量(设置成物理内存的一半):
maxmemory 4G修改服务端最大连接数据:
maxclients 10000修改连接空闲保留时间:
tcp-keepalive 60修改连接超时:
timeout 60修改tcp-backlog:
tcp-backlog 1022防火墙设置,设置6379端口可以外部防问,如果没有安装防火墙或防火墙关闭则可以不处理。
Redis集群模式配置
Redis Server
Redis配置,正常单机版配置,但注意二点:
设置appendonly:no
redis slave中增加一行:slaveof 192.168.0.12 7000
Redis Sentinel
设置对外服务地址
bind 127.0.0.1设置端口号
单机版部署redis与redis sentinel端口号不能重复
守护服务名称及服务配置信息
sentinel monitor master1 192.168.0.12 7000 2设置sentinel向master发送心跳PING来确认master是否存活时间
sentinel down-after-milliseconds master1 30000设置发生failover主备切换时,指定多少个slave同时对新的master进行同步
sentinel parallel-syncs master1 1设置sentinel像master发起ping超时最大时间
sentinel failover-timeout master1 180000关闭保护模式
Protected-mode:no
Zookeerper 集群部署
运行zookeeper命令:/bin下的zkSever.bat
在zookeeper目录下创建数据目录data,日志目录log
zookeeper配置文件zoo.cfg
设置数据目录dataDir:dataDir=../data
增加日志目录logDir:logDir=../log
设置集群信息:
在data目录新增文件myid没有后缀,在文件中输入数字,第一个zookeeper为1,第二个为2,第三为3,依此类推:
zoo.cfg中新增集群配置信息如下:
server.1=192.188.90.81:2887:3887
server.2=192.188.90.82:2887:3887
server.3=192.188.90.83:2887:3887
zookeeper的查看工具zooInspector
zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. dataDir=../data dataLog=../log # the port at which the clients will connect clientPort=2181
Jar包部署
安装前准备工作
下载JDK,地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,注请下载64位的JDK版本。
JDK、redis、数据库配置已经安装完成;
获得最的datacenter.jar包;
准备WinRAR解压工具与UE类似的编辑工具。
JDK安装
双击进行安装;
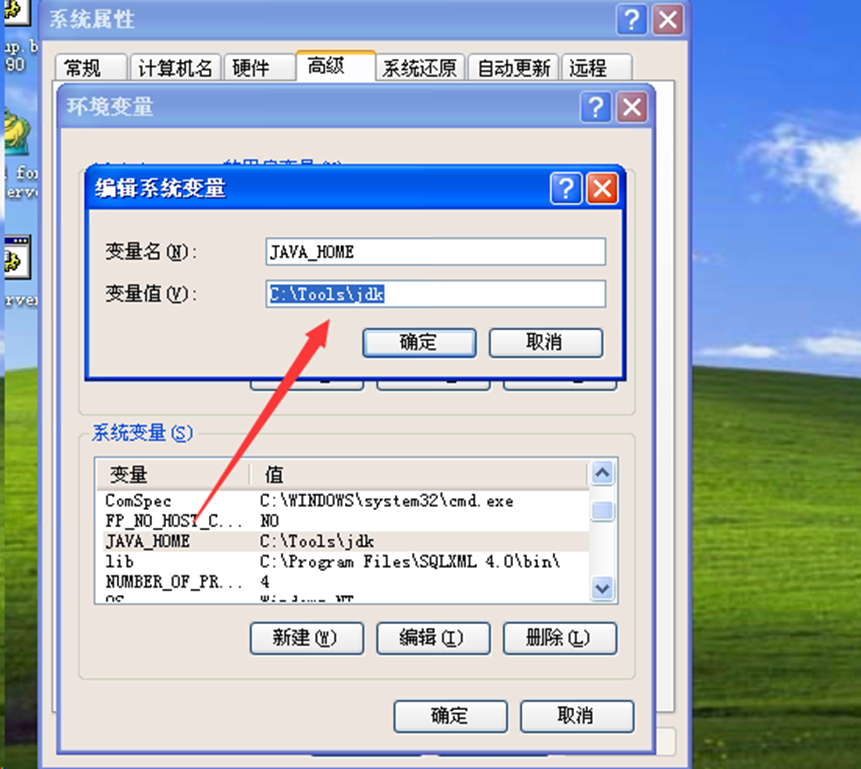
配置环境变量,JAVA_HOME与Bin路径,下面是Windows的配置
设置JAVA_HOME:
在PATH中增加
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;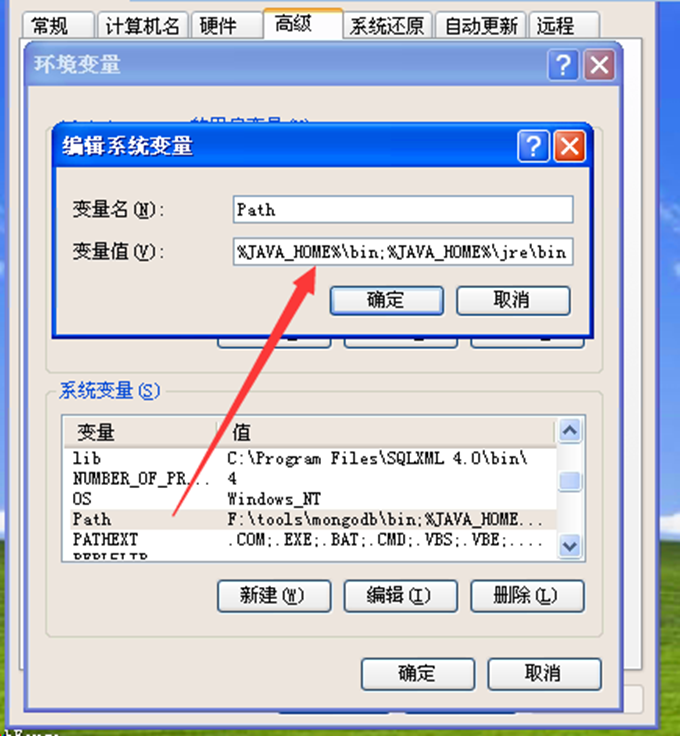
修改jar中配置文件
用winrar打开datacenter.war包;
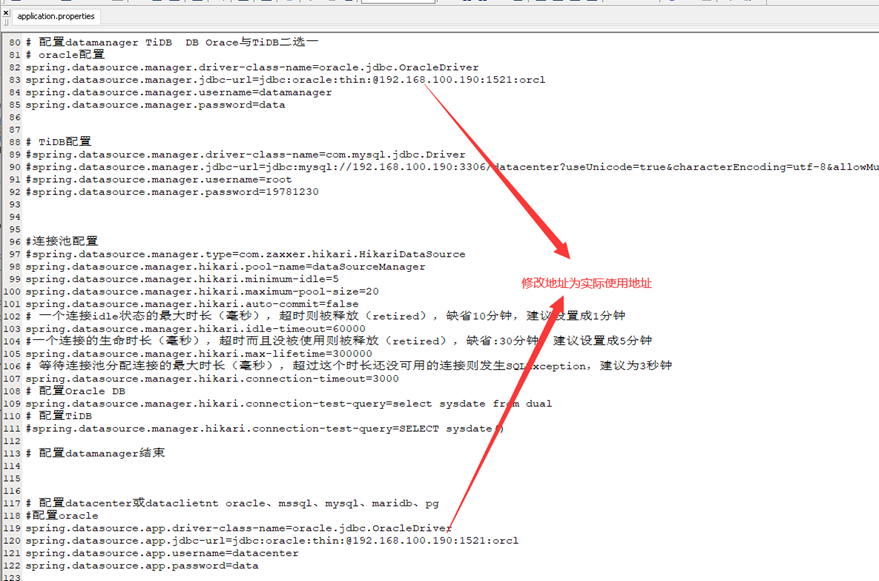
修改application.properties文件
application.properties在目录datacenter \BOOT-INF\classes下,修改Oracle数据库连接信息,如下:
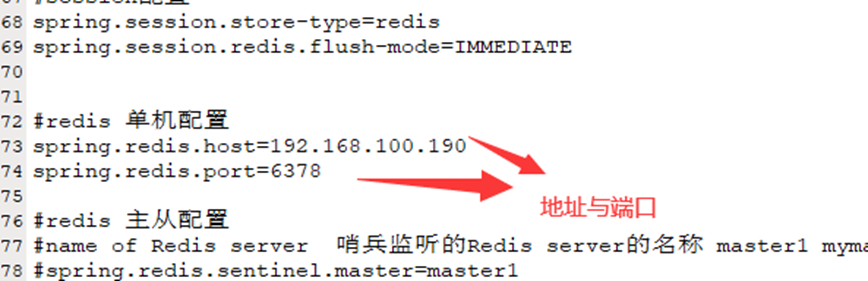
修改redis数据库连接信息,如下图:
部署datacenter.war包
拷贝修改后datacenter.jar包到新建目录springboot
创建批处理文件(bat文件)

实际环境,DataCenter不与别的服务部署在一台机器上,内存设置为物理内存一半。
启动bat文件
Portal部署
安装前准备工作
下载JDK,地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,注请下载64位的JDK版本。
JDK、redis、数据库配置已经安装完成;
获得最的datacenter.jar包;
准备WinRAR解压工具与UE类似的编辑工具。
修改配置文件
修改服务地址:
通过PLSQL用datacenter登录,修改现应的服务地址:
select t.*, t.rowid from PORTAL_VIEW t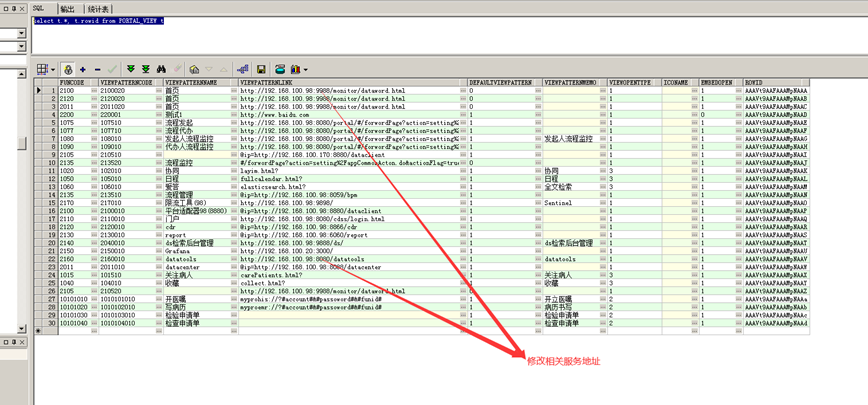
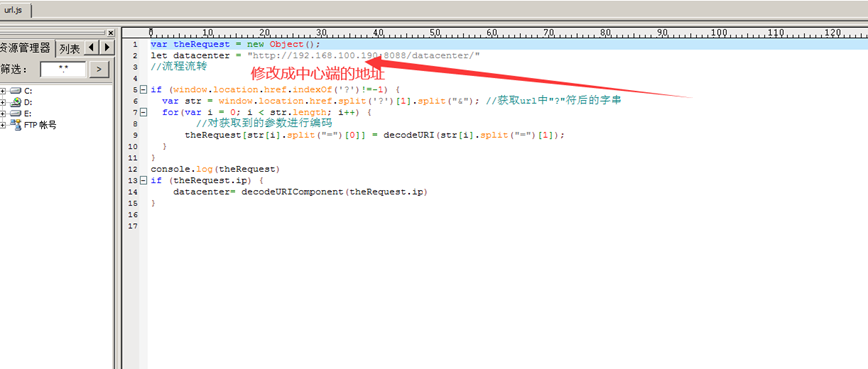
修改static\portal\bpm下面的url.js文件
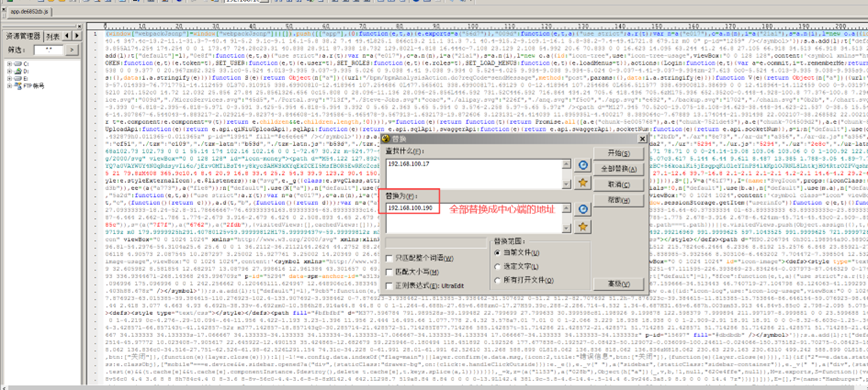
修改static\portal\static\js下面的app.js文件,如图:
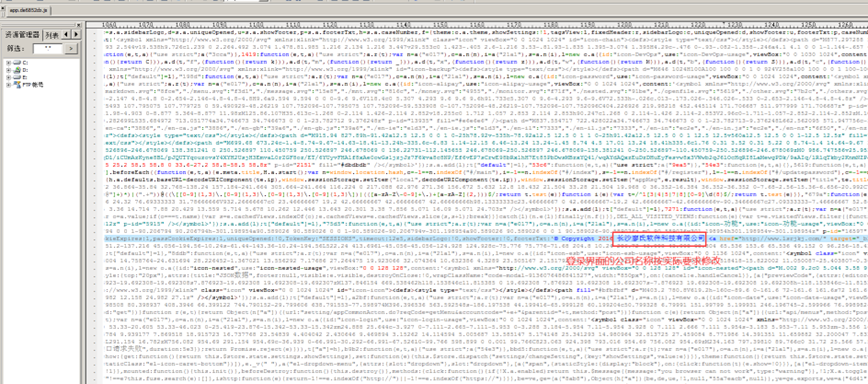
修改jar包配置文件
拷贝portal.jar包到新建springboot项目
用WinRAR打开portal.jar包;
修改application.properties文件
application.properties在目录portal\Boot-INF\classes下,
将application.properties复制到与portal.jar平级目录
修改复制的配置文件中的获取app url属性,如下图
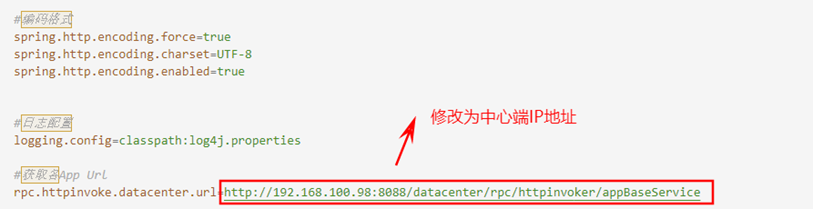
创建批处理文件(bat文件)并指定使用外部配置文件运行,如下图。

部署portal.jar包
启动bat文件
统一门户配置修改
地址: IP:8080/portal
账户:sa
密码:123456
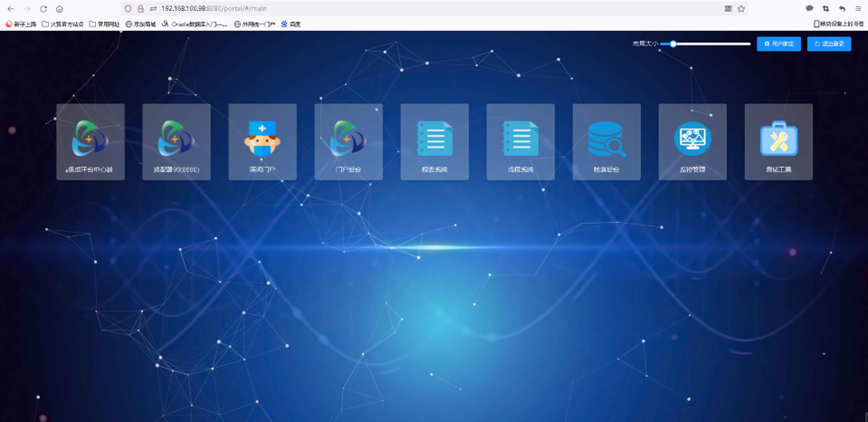
进入CDR修改模块对应的链接地址
地址:ip:8080/portal/#/login
账户:cdr 密码:data
大屏监控monitor
Jar包部署
monitor是一个springboot程序
所有的配置信息都在monitor.jar包中下BOOT-INFO\classes\application.properties
修改Oracle数据配置信息:
# 配置DB 修改Oracle IP地址 spring.datasource.url=jdbc:oracle:thin:@127.0.0.1:1521:orcl spring.datasource.username=datacenter spring.datasource.password=data修改#redis 主从配置,从再有运行环境取得
监控服务配置:
#负载均衡器,多个服务用逗号分隔 monitor.loadBalance=127.0.0.1:80 monitor.tomcat=127.0.0.1:8080 monitor.redis=127.0.0.1:6379 monitor.sentinel=127.0.0.1:7000 monitor.zookeeper=127.0.0.1:2181 monitor.oracle=127.0.0.1:1521 monitor.smsStart=1
直接双击monitor_run.bat可运行ds
访问地址为:http://ip:9988/monitor
页面屏蔽不需要的服务,=空,清理消息队列再重启服务即可
Kafka 集群部署
1、解压:
tar -zxvf kafka_2.11-2.3.1.tgz -C /usr/local/bin
2、修改配置文件
server.properties
broker.id=0
listeners=PLAINTEXT://192.168.100.98:9092
advertised.listeners=PLAINTEXT://192.168.100.98:9092
#topic的默认分割的分区个数。多分区允许消费者并行获取数据,机器数量的3倍。
num.partitions=9
#当Kafka启动时恢复数据和关闭时保存数据到磁盘时使用的线程个数。
num.recovery.threads.per.data.dir=3
#副本个数。除了开发测试外,其他情况都建议将该值设置为大于1的值以保证高可用,比如:3。
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
#Zookeeper连接字符串。是一个使用逗号分隔的host:port字符串。
zookeeper.connect=172.16.3.177:12181,172.16.3.178:12181,172.16.3.179:12181/kafka
log.dirs=./logs
3、分发
scp -r /usr/local/bin/kafka_2.11-2.3.1/ root@192.168.100.21:/usr/local/bin/kafka_2.11-2.3.1/
scp -r /usr/local/bin/kafka_2.11-2.3.1/ root@192.168.100.22:/usr/local/bin/kafka_2.11-2.3.1/
4、修改配置文件中:
#每台机器上不一样,第一台为0,第二台1,第三台为2
broker.id=0
listeners=PLAINTEXT://192.168.100.98:9092
advertised.listeners=PLAINTEXT://192.168.100.98:9092
5、启动kafka与停止:
切换目录:cd /usr/local/bin/kafka_2.11-2.3.1
启动:bin/kafka-server-start.sh -daemon config/server.properties
停止:bin/kafka-server-stop.sh
查看主题:
bin/kafka-topics.sh -list -zookeeper 192.168.100.20:2181,192.168.100.201:2181,192.168.100.22:2181
6、如果重新初始化Kafka在zookeerp中的配置信息:
cd /usr/local/bin/apache-zookeeper-3.5.6-bin/bin
./zkCli.sh -timeout 5000 -server node20:2181,node21:2181,node22:2181
删除kafka在zookeeper中的信息:deleteall /kafka
查看数据: ls /
删除指定数据:
delete /node_1/node_1_10000000001
7、Kafka查看工具:
kafkatool_64bit在windows下安装
8、要使分区比较均匀的落到不同的机器上,要在所的kafka启动完成后,同发布数据
9、其它操作:
cd /usr/local/bin/kafka_2.11-2.3.1
查看主题:
bin/kafka-topics.sh --list --bootstrap-server 192.168.100.20:9092,192.168.100.21:9092,192.168.100.22:9092
创建主题:
bin/kafka-topics.sh --create --bootstrap-server node20:9092,node21:9092,node22:9092 --replication-factor 3 --partitions 9 --topic datacenter
删除主题:
bin/kafka-topics.sh --delete --bootstrap-server node20:9092,node21:9092,node22:9092 --topic datacenter
查看分区:
bin/kafka-topics.sh --describe --bootstrap-server 192.168.100.20:9092,192.168.100.21:9092,192.168.100.22:9092
创建分区:
bin/kafka-topics.sh --alter -bootstrap-server node20:9092,node21:9092,node22:9092 --topic datacenter --partitions 9
Hadoop集群部署
1、先核对是否安装了java,如果没有安装参考照java安装
java安装目录:
whereis java
删除centos自带的openjdk
[wj@master hadoop]$ rpm -qa | grep java
java-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.5.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
tzdata-java-2018e-3.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
[root@master ~]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch
[root@master ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.5.el7.x86_64
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
[root@master ~]# rpm -e --nodeps tzdata-java-2018e-3.el7.noarch
[root@master ~]# rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
2、修改host文件
gedit /etc/hosts
增加以下信息:
192.168.100.20 node20
192.168.100.21 node21
192.168.100.22 node22
发送到集群的其它机器:
scp -r /etc/hosts root@192.168.100.21:/etc/
scp -r /etc/hosts root@192.168.100.22:/etc/
测试:
ping node21
ping node22
3、 /usr/local/bin 目录下创建文件夹(三台机器都需要做)
在root用户下创建hadoop文件夹
4设置SSH免密钥
设置20与其它机器免密钥
ssh-keygen -t rsa
ssh-copy-id node20
ssh-copy-id node21
ssh-copy-id node22
设置21与其它机器免密钥
ssh-keygen -t rsa
ssh-copy-id node20
ssh-copy-id node21
ssh-copy-id node22
设置22与其它机器免密钥
ssh-keygen -t rsa
ssh-copy-id node20
ssh-copy-id node21
ssh-copy-id node22
5、解压安装hadoop(只在一台机器上处理,最后用scp分发)
tar zxvf hadoop-2.8.3.tar.gz -C /usr/local/bin/hadoop/
6、配置hadoop集群
注意:配置文件在/usr/local/bin/hadoop/hadoop-2.8.3/etc/hadoop/下
cd /usr/local/bin/hadoop/hadoop-2.8.3/etc/hadoop
6.1修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/bin/hadoop/hadoop-2.8.3/data/full/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node20:2181,node21:2181,node22:2181</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish a server connection. </description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection. </description>
</property>
</configuration>
6.2 修改hadoop-env.sh
export JAVA_HOME=/usr/local/bin/java/jdk1.8.0_91
6.3修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>node20,node21</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node20</name>
<value>node20:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node20</name>
<value>node20:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node21</name>
<value>node21:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node21</name>
<value>node21:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.cluster</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node20:8485;node21:8485;node22:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/bin/hadoop/hadoop-2.8.3/data/journal_tmp_dir</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/bin/hadoop/hadoop-2.8.3/data/datanode/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/bin/hadoop/hadoop-2.8.3/data/datanode/name</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
</configuration>
6.4 修改slaves
node20
node21
node22
6.5修改mapred-env.sh
export JAVA_HOME=/usr/local/bin/java/jdk1.8.0_91
6.6 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.7 修改yarn-env.sh
修改 export JAVA_HOME=/usr/local/bin/java/jdk1.8.0_91
6.8 修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm0,rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm0</name>
<value>node20</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node21</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node22</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node20:2181,node21:2181,node22:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7、分发hadoop到节点(写机器别名与IP地址是一样的)
cd /usr/local/bin/hadoop
scp -r /usr/local/bin/hadoop/hadoop-2.8.3/ root@node21:/usr/local/bin/hadoop/hadoop-2.8.3/
scp -r /usr/local/bin/hadoop/hadoop-2.8.3/ root@192.168.100.22:/usr/local/bin/hadoop/hadoop-2.8.3/
8、配置环境变量
gedit /etc/profile
末尾追加
export HADOOP_HOME=/usr/local/bin/hadoop/hadoop-2.8.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib/native
编译生效 source /etc/profile
9、初始化验证集群(只运行一次)
1、如果集群是第一次启动,需要格式化namenode
cd /usr/local/bin/hadoop/hadoop-2.8.3
2、创建命名空间(格式化ZK集群):
hdfs zkfc -formatZK
3.启动journalnode集群 :安装journalnode的主机上(node20,node21,node21)上启动journalnode
hadoop-daemon.sh start journalnode
4.格式化namenode、启动namenode
1.在node20上执行: hdfs namenode -format
2.在node20上执行: hadoop-daemon.sh start namenode
3.在node21上执行: hdfs namenode -bootstrapStandby
4.在node21上执行: hadoop-daemon.sh start namenode
5.启动datanode,在node20上执行:
hadoop-daemons.sh start datanode
6.启动启动主备切换进程,(即node20和node21上都执行命令)上启动主备切换进程,ZKFC (FailoverController) 必须是在namenode节点上启动 让zk来决定用哪个namenode作为active
hadoop-daemon.sh start zkfc
10.启动与停止:
1、在安装journalnode的主机上(node20,node21,node21)上启动journalnode(等待一些时间,好像这个服务启动比较慢)
cd /usr/local/bin/hadoop/hadoop-2.8.3
hadoop-daemon.sh start journalnode
2.启动:
1.在node20上执行: hadoop-daemon.sh start namenode
2.在node21上执行: hadoop-daemon.sh start namenode
3.启动datanode,在node20上执行:
hadoop-daemons.sh start datanode
4、启动主备切换进程
在所有NameNode(即node20和node21上都执行命令)上启动主备切换进程:
hadoop-daemon.sh start zkfc
5、停止:
stop-dfs.sh
6.其它
1、启动某个namenode:
hadoop-daemon.sh start namenode
2、启动某个datanode
hadoop-daemon.sh start datanode
11、检查启动是否成功
1、启动后node20和node21都处于备机状态,将node21切换为主机(下面的命令在hadoop1上执行):
hdfs haadmin -transitionToActive node21
2、查看DataNode是否正常启动
hdfs dfsadmin -report
访问集群
浏览器 http://192.168.100.20:50070 访问集群
http://192.168.100.21:50070
12、HA的切换
由于我配置的是自动切换,若NNA节点宕掉,NNS节点会立即由standby状态切换为active状态。若是配置的手动状态,可以输入如下命令进行人工切换:
hdfs haadmin -failover --forcefence --forceactive nna nns
hdfs haadmin -getServiceState node20
11、参考文档:https://www.iteye.com/blog/chengjianxiaoxue-2174940
版本一致:https://yq.aliyun.com/articles/100913?t=t1
12、yarn启动与停止:
sbin/stop-yarn.sh
sbin/start-yarn.sh
13、yarn后台访问:
后访问:
http://h2master:8088/cluster
Flink集群部署
1、先安装Hadoop,把Flink与Hadoop安装一块,一来可以少一些服务器,另外,安装JDK及免登录的事件可节省。
2、安装:
tar -zxvf flink-1.8.2-bin-scala_2.11.tgz -C /usr/local/bin/flink/
3、修改flink.conf:
#值设置成你master节点的IP地址指向Master,但可能会发生变化,因为由zookeeper选举决定,所以不需要设定
jobmanager.rpc.address:node20
#.配置JobManager进行RPC通信的端口,使用默认的6213即可
jobmanager.rpc.port: 6123
#每个TaskManager可用的总内存
jobmanager.heap.size: 1024m
#每个节点的JVM能够分配的最大内存
taskmanager.heap.size: 1024m
#配置每一个slave节点上task的数目 等于每台机器上可用CPU的总数
taskmanager.numberOfTaskSlots: 3
# 用于未指定的程序的并行性和其他并行性,默认并行度
parallelism.default: 2
#临时目录
taskmanager.tmp.dirs:hdfs://cluster/flink/ha/tmp
io.tmp.dirs: /usr/local/bin/flink/flink-1.8.2/tmp
web.tmpdir: /usr/local/bin/flink/flink-1.8.2/tmp/web
jobmanager.web.tmpdir: hdfs://cluster/flink/ha/tmp/web
web.upload.dir: /usr/local/bin/flink/flink-1.8.2/tmp/web
# fixed-delay:固定延迟策略
restart-strategy: fixed-delay
# 尝试5次,默认Integer.MAX_VALUE
restart-strategy.fixed-delay.attempts: 5
# 设置延迟时间10s,默认为 akka.ask.timeout时间
restart-strategy.fixed-delay.delay: 10s
#Flink JobManager HA部署参考:https://www.cnblogs.com/liugh/p/7482571.html
#zookeeper地址 master高可用部署
high-availability: zookeeper
#这个地址写成实际的存储地址,可以是网络地址,也可以本机地址
high-availability.storageDir: hdfs://cluster/flink/ha
high-availability.zookeeper.quorum: 192.168.2.102:2181,192.168.2.103:2181,192.168.2.104:2181
high-availability.zookeeper.path.root: /flink
# high-availability.cluster-id: /cluster_one
state.backend: filesystem
state.checkpoints.dir: hdfs://cluster/flink/flink-checkpoints
state.savepoints.dir: hdfs://cluster/flink/flink-checkpoints
state.backend.fs.checkpointdir: hdfs://cluster/flink/flink-checkpoints
state.checkpoints.num-retained: 3
4、#master(jobmanager)配置文件 slave(taskmanager)配置文件
配置:master与slave
master:
node20:8081
node21:8081
slave:
node20
node21
node22
5、Copy flink-shaded-hadoop2-uber-2.8.3-1.8.2.jar 到/usr/local/bin/flink/flink-1.8.2/bin目录下,连接Hadoop组件
6、分发到别的机器上
scp -r /usr/local/bin/flink/flink-1.8.2/ root@192.168.100.21:/usr/local/bin/flink/flink-1.8.2/
scp -r /usr/local/bin/flink/flink-1.8.2/ root@192.168.100.22:/usr/local/bin/flink/flink-1.8.2/
7、启动与停止:
cd /usr/local/bin/flink/flink-1.8.2/bin
1.集群方式启动或关闭flink:
启动: ./start-cluster.sh
停止: ./stop-cluster.sh
关闭(某个): ./jobmanager.sh stop
访问:
http://192.168.100.20:8081
2.启动或关闭jobManager某个jobmanager(不要用这个):
启动(master):
./jobmanager.sh start node20 8081
或:
./jobmanager.sh start node21 8081
关闭(所有): ./jobmanager.sh stop-all
3.启动或关闭taskmanager:
启动: ./taskmanager.sh start
关闭(某个): ./taskmanager.sh stop
关闭(所有): ./taskmanager.sh stop-all
8、查看zookeeper中flink信息:
cd /usr/local/bin/apache-zookeeper-3.5.6-bin/bin
./zkCli.sh -timeout 5000 -server node20:2181,node21:2181,node22:2181
flink目录信息:ls /flink/clusterflink
当前flink master信息:get /flink/clusterflink/leader/rest_server_lock
9、如果hadoop运行过程后面格式化,需要删除zookeeper中的flink信息:
cd /usr/local/bin/apache-zookeeper-3.5.6-bin/bin
./zkCli.sh -timeout 5000 -server node20:2181,node21:2181,node22:2181
先删除子目录,再让上删除主目录
deleteall /flink/clusterflink
deleteall /flink
删除指定数据:
delete /node_1/node_1_10000000001
9、hadoop flink文件存储信息:
查看文件存储信息: hadoop fs -ls /flink
删除文件存储信息: hadoop fs -rm -r /flink
清空回车站: hdfs dfs -expunge
10、参考:
https://www.jianshu.com/p/c743041e55b0
https://www.cnblogs.com/leon0/p/11606699.html
https://blog.csdn.net/bao_since/article/details/90234181